

東証のシステム障害は前代未聞の事件だったワンね。
偉い人の会見を見てもいまいち理解できなかったけど、原因は何だったワンか。
どのような再発防止策が考えられるか教えてほしいワン。

こんな方に向けた記事となっております。
現役システムエンジニアとして技術者視点で東証システム障害の発生事象、原因、考えられる再発防止策について解説して行きます。
東証システム障害の発生事象

2020年10月1日、東京証券取引所(東証)のシステム障害が発生し、全銘柄の売買が終日停止する未曽有の事態が発生しました。
東証システム全体が停止するのは2005年11月以来のこと。
1日の平均売買金額は3.0兆円と言われているため、システム停止によって多くの株主や投資家に甚大な影響を与えました。
10月1日は日銀短観の発表日である点、広島で県内シェア首位のひろぎんホールディングスなど3社の上場を予定されていた点から、企業側への影響も計り知れません。
発生経緯
システム障害が発生した10月1日の経緯は以下の通りです。
- 午前7時04分 冗長化された共有ディスク装置1号機でメモリ故障が発生
- 午前8時11分 東証が事象発生について把握
- 午前8時36分 システム障害が発生していることを関係者へ通知
- 午前8時54分 取引開始前に相場参加者を接続するゲートウェイを遮断
東証システムは注文売買系ネットワークと運用系ネットワークに分かれています。
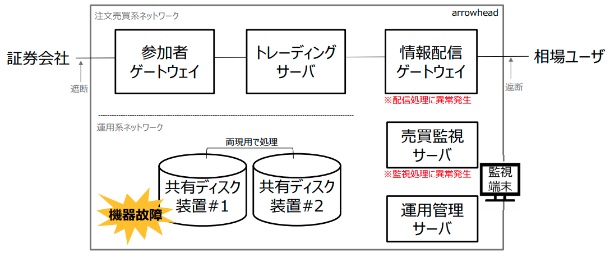
システム障害が発生したのは運用系ネットワークにある共有ディスク装置でした。
共有ディスク装置とは
共有ディスク装置とは、業務処理を行うサーバとは別でデータを格納する装置です。
共有ディスク装置を使うメリットは以下の通りです。
- サーバのディスク容量上限を気にせずに、大容量のデータを格納できる。
- データ格納個所を外出しすることで、複数サーバから共有ディスク装置内のデータを参照できる。
あなたのご自宅にもある外付けハードディスクも共有ディスク装置の1つと言えます。
外付けハードディスクはサブPCや他人のPCにUSB接続してもデータを読み取ることができますよね。
東証のシステムでは各証券会社との売買データ、相場情報の配信データを大量に取り扱っていることが想定されるため、共有ディスク装置の利用は必須であると言えます。
なお共有ディスク装置は外付けハードディスクのようにディスク機能のみ有している装置ではなく、NASのようなOS機能を有しているファイルサーバであったと考えられます。
冗長化とは
冗長化とは2台以上の装置で同じ機能を実装することで、片方の装置に障害があった場合に残りの片方でサービス継続するためのしくみです。
東証システムは共有ディスク装置を2台で冗長化することで、有事の際もサービス継続できるよう設計されています。
共有ディスク1号機でメモリ故障が発生した際、通常であれば共有ディスク2号機に切り替わってサービスを継続できるはずでしたが、正常に切り替わらなかったためサービス継続ができない状況となりました。
冗長化には以下2つの方式があります。
Active-Active(アクティブ/アクティブ)
正常時に2台両方とも稼働させ、処理を分散させる方式。有事の際には1台を切り離し、1台の縮退運転でサービスを継続させる。
Active-Standby(アクティブ/スタンバイ)
正常時に1台のみ稼働させ、もう1台は待機させる方式。有事の際にはフェイルオーバーで待機している1台に切り替えることでサービスを継続させる。
東証の会見では、両現用の共有ディスクでフェイルオーバーによって切り替えを試みたと言った説明がありましたので、Active-Standbyの構成であると考えられます。
初動対応は問題なかったのか
共有ディスク装置の故障からゲートウェイ遮断の対処まで1時間50分を要していますが、午前9時の売買開始までに間に合っているため、故障したまま売買が開始されてしまう最悪の状況は免れました。
強いて言えば、自動ではなく手動フェイルオーバーを行うことで早期復旧を試みる選択肢もありました。
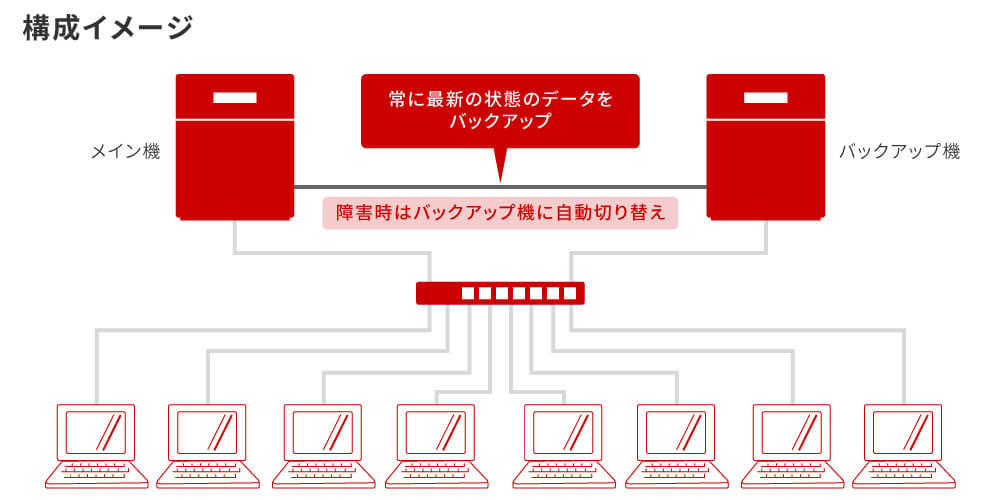
上記は東証システムのシステム構成図ではありませんが、一般的なフェイルオーバーのしくみを表した図です。
フェイルオーバーではメイン機である1号機からバックアップ機である2号機に、常に最新の状態のデータをバックアップします。
本事象では1号機のメモリ異常によってデータの正常性が確認できない状態となったため、何も考えずに切り替えを行ってしまうと1号機と2号機の間でデータ不整合が生じるリスクがありました。
東証の会見でも手動フェイルオーバーでの対処はシステム影響を踏まえて実施しなかった旨の説明がありました。
自動で切り替わらなかったことが史上初の事態であったことから、復旧対応のマニュアルにはない想定外の状況となったと考えられます。
また、データの整合性が保証されないまま復旧優先で対処してしまっては、企業・株主・投資家に誤ったデータが表示され混乱を招くリスクがあると考え、当日の復旧を見合わせるという苦渋の決断を下したと考えられます。
東証システム障害の原因

前章でも触れましたが、システム障害の発生原因は以下の2点です。
- 共有ディスク装置1号機でメモリ故障が発生した
- 共有ディスク装置1号機から共有ディスク装置2号機に正常に切り替わらなかった
前者のメモリ故障については、ハードウェアは必ずいつか壊れるものなので、ある意味仕方がありません。
2号機に切り替わらなかったという後者が本事象の根本原因であると言えます。
正常に切り替わらなかった原因については現時点で明らかになっていませんが、以下が考えられます。
- 共有ディスク装置が完全に停止しなかった
- フェイルオーバーのヘルスチェックが動作しなかった
共有ディスク装置が完全に停止しなかった
共有ディスク装置でメモリ故障が発生した際、共有ディスク装置のOSがメモリ故障を認識できず、正常時と同様に動作しようと試みたと考えられます。
人間で例えるなら、心臓は動いているけど脳(=厳密に言うとメモリではなくCPUに相当)が動かない脳死状態であったと言えます。
ヘルスチェックが正常に動作しなかった
装置が正常状態であるか異常状態であるかを自動で監視するしくみを、ヘルスチェックと言います。
監視環境から共有ディスク装置1号機へのヘルスチェック結果で異常状態だと判定された場合、1号機から2号機へのフェイルオーバーが発生します。
このヘルスチェックが正常に動作しない状態であった場合、もしくは1号機の異常状態を判定できない状態であった場合、フェイルオーバーが発動せず自然復旧できなかったと考えられます。
東証システム障害の再発防止策

共有ディスク装置が正常に切り替わらかった2つの原因に対して、筆者が考える再発防止策は以下の通りです。
- 共有ディスク装置の自爆機能を追加する
- 監視環境のヘルスチェック機能が動作するよう修正する
共有ディスク装置の自爆機能を追加する
共有ディスク装置が完全に停止しなかった場合、自爆機能によって自らシャットダウン処理を行う対策です。
共有ディスク装置1号機が自爆した後、監視環境のヘルスチェック機能が1号機の停止を検知できるようになるため、フェールオーバーが発動します。
但し、完全に停止しない状態であることを共有ディスク装置自らが正確に検知できることが条件となります。
例えば、本事象のメモリ故障を表す固有のアラートが発生していれば、そのアラートを起点とした自爆機能を実装することが可能です。
異常状態でないにもかかわらず装置が自爆してしまっては元も子もないため、慎重に実装する必要があります。
ヘルスチェックが正常動作するよう修正する
もし何らかの理由でヘルスチェックを行う監視環境が停止していた場合、フェイルオーバーが発動しないのは当たり前です。
また、監視環境のリソース状況が高負荷となっていて監視できない状況であった際も同様です。
この場合は、監視環境を冗長化したり、監視環境が正常に稼働していることを更に別の監視環境で定期的に確認するという対策が考えられます。
冗長化されていない環境をシングル構成と言いますが、監視環境がシングル構成となっていて、いざという時に監視できないというのはよくある話です。
実際はコスト面を考慮して実装していなかったり、監視環境側が停止することが盲点となっていて実装が必要であるという発想に至らないことがありますが、日本経済に大きな影響を与える東証システムではきっと実装されている…と信じたいものです。
まとめ

東証システム障害について重要なポイントは以下の通りです。
- 共有ディスク装置の故障ではなく、正常に切り替わらなかったことが根本原因である
- 正常に切り替わらなかった点に焦点をあてて再発防止策を検討する必要がある
同じシステム障害が二度と同じ事象が発生しないよう、どのような再発防止策が発表されるか見ものだワン。
これからもアンテナを高く張ってニュースを確認してみるだワン。



